
AI, ML, IoT…… Big Data
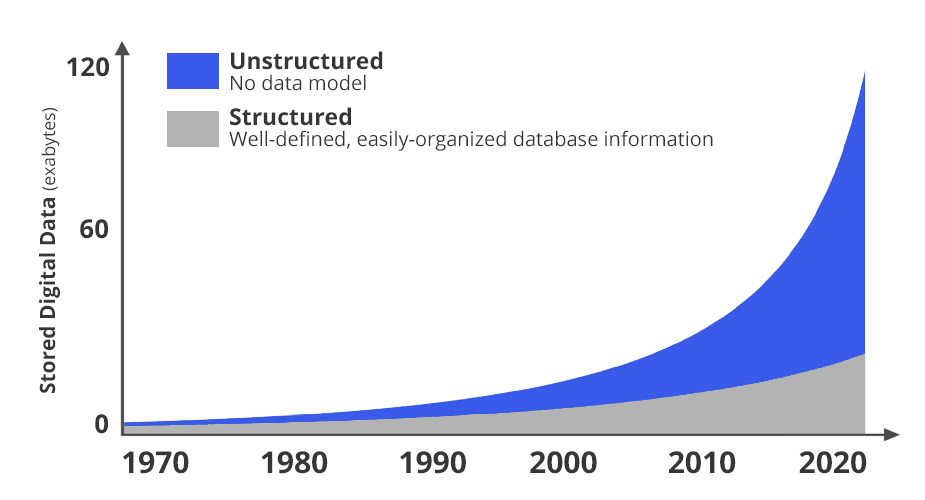
In today’s data-intensive world, much enterprise focus settles on analytics; in other words, the central problem becomes what to do with all the data you’ve collected. It’s an important problem to solve, but you’ll never get there if you don’t have an efficient, long-term data storage solution to provide a stable foundation. After all, you can’t analyze data if you have nowhere to put it.
My Mount Everest grows every year,
These are some of the most important potential data storage issues you’ll need to consider:
- Infrastructure. Data needs a place to rest, the same way objects need a shelf or container; data must occupy space. If you plan on storing vast amounts of data, you’ll need the infrastructure necessary to store it, which often means investing in high-tech servers that will occupy significant space in your office or building.
- Cost. Running your own data center is an expensive operation. You’ll need to spend money on initial setup, ongoing maintenance, and the costs associated with the people responsible for maintaining it.
- Security.Security is a major issue to overcome. Hypothetically, if your data is stored somewhere, it’s possible for a third party to obtain it. There are many layers of security that can help you prevent this unauthorized access, including encryption and reliance on third-party providers, but there’s a limit to how well these can protect you—even the FBI has trouble maintaining the security of its data when its own best practices aren’t followed. You’ll need to run a tight operation, choosing the best partners and keeping your own team adhering to best practices at all times.
- Corruption. Practically every form of data storage has the potential to be corrupted. Stray particles can interfere with most forms of data storage, and anything relying on magnetic strips or electric storage can be corrupted by electromagnetic interference. Even if there isn’t an outside source directly interfering with it, data can naturally degrade over time. Your best bet for protection here is utilizing multiple backups.
- Scale.You might be able to find a storage solution that serves your current needs adequately, but what happens if those needs change suddenly? How will you account for your needs as they stand in 5 years? Your data storage solution needs some capacity to scale. Here, it pays to give yourself as many options as possible, since you won’t be sure exactly how your needs will change in the future.
- UI and accessibility. Your data won’t be much good to you if it’s hard to access; after all, data storage is just a temporary measure so you can later analyze the data and put it to good use. Accordingly, you’ll need some kind of system with an intuitive, accessible user interface (UI), and clean accessibility for whatever functionality you want.
- Compatibility. If you plan on using multiple systems or applications with your data, you’ll need to ensure they’re compatible. For that, you will need to find a data storage partner with an open API and a clean system of transition.
I can’t see the summit…

These problems can be made even worse, depending on a handful of variables that may apply to your organization:
- The more data you need to store, the more complex these problems will become. What works cleanly for a small volume of data may not work the same for bigger demands.
- You might not be able to predict your short-term or long-term storage needs. This makes it nearly impossible to respond with agility or accurately forecast your future demand.
- Other parties. Most organizations need to secure the agreement of multiple internal leaders and external partners when making a data-related decision. This can slow down the process.
Fortunately, there’s a constant pace of innovation finding newer and better solutions to these persistent data storage problems. The better you understand the core problems facing you in data storage, the better solutions you can invent to fix them.
AWS Storage Gateway’s File Gateway

File Gateway enables you to store and access objects in Amazon S3 from file-based applications. There are a lot of applications that can benefit from S3 on the back-end, but don’t have native support for the S3 API. This is where File Gateway really shines, enabling access to S3 over file sharing protocols when the application does not have native support for the S3 API.
Several years ago, I worked with a customer that had medical data, and wanted to use Amazon S3 for the scalability, security, and ability to replicate to another AWS Region. The problem for this customer was that the application did not support the S3 API, and only supported NFS for storing and retrieving data. File Gateway was the perfect bridge for this customer as they moved into AWS and modified their application to support the S3 API natively. They were able to move their data into S3, and then use File Gateway to provide access to the data for their application, which was still running in their data center. For this customer and many others, File Gateway was the entry point to AWS, and eventually this customer moved the application into Amazon EC2 and added native S3 support. With File Gateway, the data stays in its native format. This enables you to use all of the applications and tools in the S3 universe to interrogate, manage, and find new value in the data.
Amazon FSx for Windows File Server

Amazon FSx provides native Windows-based SMB file shares for use on premises or inside of AWS. The service provides a fully managed Windows Server, including features like automated backup, patches, security, encryption, monitoring and logging, and redundancy – all for pennies per GB. Amazon FSx also gives you access to SMB, de-duplication, compression, encryption, shadow copies, and user quotas, all within AWS using Windows Server at the core. Getting access to all of these features makes it easy to replace a file server environment for SMB clients with a fully managed solution. If you have ever had to patch operating systems, and hope that the server reboots successfully, you know why having a managed environment is so important (and time-saving).
Scalable performance is another highlight of Amazon FSx. File systems can use SDD or HDD storage, and capacity and performance are scalable after you have created a file system. This enables you to provision what you need today, and grow tomorrow without needing to start over or migrate data. You also have PowerShell and the AWS Management Console, which combine for a powerful management tool. In addition, with support for on-premises Active Directory or Active Directory in AWS, you have the flexibility to deploy Amazon FSx at any point in your journey to the cloud.
Conclusion
When you need to access S3 using a file system protocol, use File Gateway. You get a local cache in the gateway that provides high throughput and low latency over SMB. Your users can mount the share and access data in the S3 bucket, and applications that support the native S3 API can continue to work that way. Older applications that don’t support the S3 API can start using S3 today with SMB or NFS.
For your native Windows workloads and users, or your SMB clients, Amazon FSx for Windows File Server provides all of the benefits of a native Windows SMB environment that is fully managed and secured, and scaled like any other AWS service. You get detailed reporting, replication, backup, fail-over, and support for native Windows tools like DFS and Active Directory.
Credits
Larry Alton
Larry is an independent business consultant specializing in tech, social media trends, business, and entrepreneurship.
Everett Dolgner
Everett is a 22-year veteran of the data storage industry. Everett currently lives in Berlin, Germany, and leads the Storage Specialist SA team at AWS.
Author: Puneet Singh
Recent Comments